데이터베이스 (Database)
데이터베이스 (Database)
다수의 사람들이 공유하여사용 할 목적으로 통합 관리되는 데이터들의 모임
오라클 설치 후 접근 방법
CMD 창 - sqlplus 입력

데이터 베이스를 사용할 수 있는 "사용자 계정"을 만들기
create user 사용자이름 identified by 암호;
권한 주기 (Grant)
grant 권한명, ----- to 사용자이름;
grant connect, resource, dba to 사용자 이름;
- connect : 사용자로 하여금 접근할 수 있도록 하는 권한
- resource : 트리거, 시퀀스, 타입, 프로시저, 테이블 등을 사용 할 수 있도록 하는 권한, 이게 없으면 테이블 생성 불가능.
- dba : 해당 사용자가 소유한 DB를 관리할 수 있고, 작성 / 변경 / 제거 등을 할 수 있는 모든 권한\
테이블 만들기 (Create)
create table 테이블이름 (속성이름 자료형, ---------)
create table member(id, pwd, name);

오라클에서 자료형
- char : 고정형 (2000바이트)
- varchar2 = varchar : 가변 문자 입력 (4000바이트)
- number : 숫자형 타입의 데이터
- date : 날짜를 위한 자료형
테이블 검색(desc)
desc 테이블명

테이블에 자료 추가하기 (insert)
1. insert into 테이블 values(값1, 값2)
2. insert into 테이블 (속성명1, 속성명2) values (값1, 값2);
insert into member values ('hong', '홍길동', 20);
insert into member(속성명1, 속성명2) values (값1, 값2);
- 값의 순서는 테이블 구조의 속성의 수와 순서가 동일 해야함
- 오라클에서는 문자와 문자열의 처리를 동일하게 하려면 홋따옴표(' ')로 묶어서 표현

데이터 조회 방법 (Select)
select 컬럼이름1, 컬럼이름2,,,,,,from 테이블명

데이터 수정하기 (Update)
update 테이블명 set 컬럼1 = 값, 컬럼2 = 값2, 컬럼3 = 값3 where 조건식;

String sql = "UPDATE member SET name = '" + name + "', " + "age= " + age + " WHERE id='"+ id +"'";데이터 삭제 (Delete)
delete 테이블이름;
delete 테이블이름 where 조건식;

String sql = "Delete member where id = '" + id + "'";컬럼의 폭을 설정
1. cmd 에서 'ed ff' 입력 후 아래 그림과 같이 테이블 당 format을 입력
2. @ff 입력하여 적용시키기

Java Database Connection Programming(JDBC)
- 자바가 데이터베이스에 연결하여 데이터베이스 명령어를 실행하는 프로그램
이클립스 <-> 오라클 연동 방법
1. 오라클 설치된 폴더에서 ojdbc8.jar 드라이버를 복사하여 java 설치 경로로 복사합니다.
오라클 설치된 폴더 (복사)

java 설치 경로(붙여넣기)

2. 이클립스에서 설정
'프로젝트 우클릭' -> 최하단 'properties' - 'Java Build Path' - 'Libraries' - 'Classpath' - 'Add External JARS' - '
apply and Close'

3. 코드에 아래와 같이 입력
- jdbc 드라이버를 메모리로 로드한다.
Class.forName("oracle.jdbc.driver.OracleDriver");- DB 서버에 연결한다
DriverManager.getConnection("jdbc:oracle:thin:
@IP주소:1521:XE", "c##sist", "sist");- 데이터베이스 명령을 실행하기 위한 객체를 생성
Statement stmt = conn.createStatement();- 데이터베이스 명령을 실행한다.
stmt.executeUpdate(sql);- 사용이 끝난 자원을 닫아준다.
- 가장 나중에 사용했던 자원부터 닫아줄 것.
stmt.close();
conn.close();Oracle 에러 발생
The Network Adapter could not establish the connection

C:\app\ChangHee\product\21c\homes\OraDB21Home1\network\admin

- tnsnames.ora, listener.ora 파일의 host 가 현재 IP인지 확인
- 재기동

ORA-12505 에러 발생

- tnsnames.ora, listener.ora 의 host 이름을 컴퓨터 이름으로 해볼 것
- 재기동
executeUpdate / executeQuery
executeUpdate (Insert, Create, 등)
- 데이터 베이스에 변경이 있는 명령을 실행할 때 사용
- 반환 값은 레코드 수를 반환한다.
executQuery (Select 등)
- 데이터베이스로부터 읽어오는 명령을 실행할 때 사용 (select)
- 읽어온 결과를 받을때는 ResultSet 반환받음.
- ResultSet 의 next()함수로 데이터를 next, next하면서 데이터가 있는 만큼 실행가능
- next() 실행 시 다음 행을 바라보는 개념
ResultSet rs = stmt.executeQuery(sql);
while (rs.next()) {
String id = rs.getString(1);
String name = rs.getString(2);
int age = rs.getInt(3);
System.out.println("번호: " + id);
System.out.println("이름: " + name);
System.out.println("나이: " + age);
System.out.println("-----------------");
}
아래 그림과 같은 형식으로 사용자 표현
2022.04.18 - [분류 전체보기] - 사용자 등록/ 수정/ 삭제/ 목록 리스트 출력

오라클 참조 키 만들기
- table 생성 시 references 키워드 이용
컬럼 자료형 references 참조할 테이블(참조할 컬럼)
1 2 3 4 5
예시)
custid NUMBER REFERENCES customer(custid)
1 2 3 4 5
SQL 기능에 따른 분류
1. 데이터 정의어(DDL)
- 테이블이나 관계의 구조를 생성하는 데 사용
- 테이블을 만들거나 테이블의 구조를 변경하거나 데이터를 삭제하는 명령
CREATE, ALTER, DROP
2. 데이터 조작어(DML)
- 테이블에 데이터를 검색, 삽입, 수정 ,삭제하는데 사용
SELECT, INSERT, DELETE, UPDATE
3. 데이터 제어어(DCL)
- 데이터의 사용 권한을 관리
GRANT, REVOKE 등
데이터 정의어 (DDL) - CREATE
- 테이블을 생성하는 명령
CRATE TABLE 테이블이름
( 컬럼이름 데이터타입 제약사항들[ NOT NULL | UNIQUE | DEFAULT | CHECK | 등]
..
..
)
NOT NULL
: NULL을 허용하지 않음(무조건 값을 넣어라)
UNIQUE
: 중복 불가능, NULL 허용
DEFAULT
: 기본 값
CHECK
: 컬럼의 값이 특정 조건식을 만족 해야함
FOREIGN KEY
:참조키 설정, 다른 테이블의 값을 참조
:부모테이블의 PK를 FK로 설정할 수 있음
PRIMARY KEY
: 기본키 설정, 중복 불가, 생략 불가
: 두개 이상의 컬럼을 한 쌍으로하여 기본키로 설정할 수 있음
: 두개 이상의 컬럼을 기본키로 설정할 경우
테이블 생성 시 테이블 레벨에서 PRIMARY KEY (속성1, 속성2)
| FOREIGN KEY | NOT NULL | PRIMARY KEY | UNIQUE | CHECK | DEFAULT | |
| 생략 | O | X | X | O | O | DEFAULT 값 |
| 중복 | O | O | X | X | O | O |
추가 설명 - CHECK
- 컬럼의 값이 특정 조건식을 만족 해야함
- 아래와 같이 제약조건을 설정할 수 있음.

Check 제약조건 위배시 - 에러 출력

데이터 정의어 (DDL) - ALTER
- 테이블 구조 변경하는 명령
- 테이블에 새로운 컬럼명을 추가 / 삭제
- 제약조건을 추가 / 삭제
- 자료형 변경, PK, FK 설정 가능.
컬럼 추가
ALTER TABLE 테이블명 ADD 컬럼이름 자료형;
컬럼에 PK 추가
ALTER TABLE 테이블명 ADD PRIMARY KEY (컬럼이름, [컬럼이름2]);
- 단, 이미 컬럼 데이터로 null값이 들어가 있는 상태면 바꿀 수 없음
컬럼에 FK 추가
ALTER TABLE 테이블명 ADD FOREIGN KEY(컬럼이름) REFERENCES 부모테이블명(컬럼명)
- 단, 이미 컬럼 데이터로 null값이 들어가 있는 상태면 바꿀 수 없음
컬럼에 CHECK 추가
ALTER TABLE 테이블명 ADD CHECK (price<=20000);
컬럼 자료형 변경
ALTER TABLE 테이블명 modify 컬럼이름 새로운자료형
컬럼 NOT NULL 설정
ALTER TABLE 테이블명 modify 컬럼이름 NOT NULL
컬럼 삭제
ALTER TABLE 테이블명 DROP COLUMN 컬럼이름
데이터 정의어 (DDL) - DROP
- 테이블 삭제하는 명령
DROP TABLE 테이블명;
관계형 데이터베이스에서는 테이블을 개체(Entity)라고도 표현한다.
개체무결성
- 모든레코드 (튜플)는 PK로 설정된 주식별자에 의해서 구별이 가능해야 함을 말한다.
- pk는 null이 될 수 없고, 중복을 허용하지 않는다.
- 이것을 만족하지 않는 경우를 '개체 무결성에 위배된다'라고 말한다.
참조무결성
- 참조키로 설정된 컬럼의 값은 반드시 부모테이블 존재해야한다
- 이것을 만족하지 않는 경우를 '참조 무결성에 위배된다'라고 말한다.
on delete cascade
- 부모테이블의 레코드를 삭제 할 때에 연쇄적으로 자식의 레코드를 삭제하도록 설정
- 자식 테이블 생성 시에 설정 해줘야 함
FOREIGN KEY ( 자식 속성 ) REFERENCES 부모테이블(부모속성) ON DELETE CASCADE

데이터 조작어 (DML) - SELECT
SELECT [ ALL | DISTINCT ] 속성이름
FROM 테이블이름(들)
[WHERE 검색조건(들)]
[GROUP BY 속성이름]
[HAVING 'GROUP BY'에 대한 검색조건(들)]
[ORDER BY 속성이름 [ASC | DESC]]
WHERE
비교 : = , <>, <, <=, > >=
범위 : BETWEEN -- BETWEEN A AND B
집합 : IN, NOT IN -- price IN(10000, 20000, 30000)
패턴 : LIKE ( bookname LIKE '축구의 역사' ) ) , %와 같이 많이 사용 됌.
NULL : IS NULL, IS NOT NULL
복합 : AND, OR, NOT
- 'IN'과 'NOT IN' 은 각각 'OR'과 '<> AND' 로 표현할 수 있다.
'NOT IN' 과 '<> AND' 예시

- 와일드문자

'축구'가 포함된 속성 출력

두번째 글자에 '구'가 포함되고 뒤에는 아무 글자나 와도 됌
- 언더바( _ ) 로 인해 첫글자 패스
- 퍼센트 ( % ) 로 인해 '구'이후의 글자 아무거나 와도 상관없음

ORDER BY
- 특정 컬럼을 기준으로 자료를 정렬하여 검색하고자 할 떄 사용.
1. order by 컬럼이름 [asc, desc]
2. order by 컬럼1, 컬럼2
--> 이 경우 컬럼1로 먼저 정렬 되고, 정렬 되던 도중 같은 값이 존재하면 컬럼2로 정렬됨
----------------------------------
asc : 오름차순 (기본, 생략가능)
desc : 내림차순
- order by 로 속성 명이 2개가 오면 뒤에 온 필드명은 선행 필드로 정렬 후 값이 동일 할 경우 후행 필드로 정렬됨
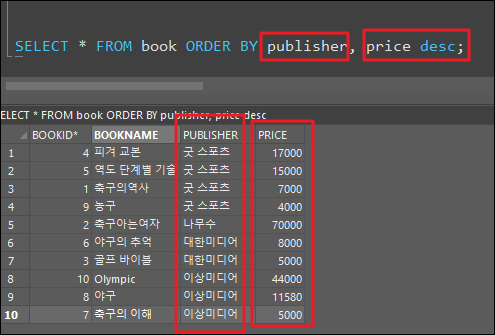
'publisher' 컬럼으로 정렬 후
컬럼의 데이터가 동일할 경우 가격순으로 내림차순 정렬
집계함수
- 컬럼 별 총합, 평균, 최대 값, 최소 값, 개수를 파악하기 위한 함수
- AS 키워드로 별칭을 줄 수 있다
- 집계함수의 결과는 다른 컬럼의 이름을 함께 출력할 수 없음
SUM (총합)
AVG (평균)
MAX (최대 값)
MIN (최소 값)
COUNT (개수)
-> 컬럼에 null이 있으면 COUNT(*)로 해야 null값 까지 카운트
-> 컬럼에 null이 있을 때 COUNT(컬럼명) 하면 null값 카운트 불가능
---------------------------------------
예시
select SUM (saleprice) from orders;
select AVG (saleprice) from orders;
집계함수의 결과는 다른 단일 컬럼의 이름을 함께 출력할 수 없음

GROUP BY 와 집계함수
- 집계함수의 결과는 다른 단일 컬럼의 이름을 함께 출력할 수 없는데,(한줄만 표현됨)
- 고객 별로 총 추문건수를 알고 싶을 경우 GROUP BY와 같이 사용하여 표현 가능
- 만약 group by 안쓰면 전체 행의 개수와, saleprice의 합계만 1행 2열로 출력될 것임
Group by 미 사용 시 한줄로 밖에 표현 못함.

출판사 컬럼을 Group by로 묶어주어 아래와 여러 데이터 표현 가능
출판사 별로 출판한 책 개수를 표현한 것임

HAVING
- GROUP BY 절에 나타난 결과에 대해 조건식을 표현하고자 할 때에 사용
- 즉, GROUP BY의 where이라고 생각할 것
- 조건식에서는 alias를 사용할 수 없는 듯
ex) alias가 "건수"라고 한다면 '건수 >=2' 이런 식으로 사용 불가능
데이터 조작어 (DML) - INSERT
INSERT INTO 테이블명 VALUES (값 리스트);
- 값 리스트는 테이블의 구조와 동일해야 함 (타입, 순서 등)
INSERT INTO 테이블명 [(속성리스트)] VALUES (값 리스트);
- 값 리스트는 속성리스트의 구조 동일해야함
- 테이블의 제약조건에 'NOT NULL', 'PK'가 존재한다면 속성 리스트에 반드시 포함해야한다
INSERT INTO 테이블명1 [(속성리스트)] SELECT 속성 FROM 테이블명2
- SELECT 구문의 테이블명2의 레코드들을 테이블명1로 INSERT 가능
데이터 조작어 (DML) - UPDATE
- 조건식이 없으면 모든 레코드의 값이 수정 됨
- 조건식이 있으면 조건에 맞는 레코드만 수정 됨
UPDATE 테이블명
SET 속성이름1 = 값1 [ , 속성이름2 = 값2, ........]
where [<검색조건>];
UPDATE 테이블명
SET 속성이름1 = ( 서브쿼리 SELECT )
데이터 조작어 (DML) - DELETE
DELETE 테이블명 [where 조건식]
ROLLBACK
- DML 작업 시 가장 최근의 commit 지점까지 취소
- DCL, DDL은 자동 커밋
- 아래 예시와 같은 경우 Rollback 불가능
작업 순서
1. update 작업 진행
2. create table 작업 진행
3. Rollback하여 1번의 update 진행 전으로 RollBack 이 가능한가?
--> 불가능, 이유는 2번의 create 작업을 진행하면 자동 commit이 되기 때문에 1번 update 전으로 rollback이 무시됨
Join
- 관계형 데이터베이스에서 검색하고자 하는 컬럼이 두개 이상의 테이블에 있을 때에 조인을 사용
- 테이블과 테이블 간에 참조관계이 있을 경우 사용 가능
where 절에 아래와 같이 join식을 적어준다
WHERE
..
..
..
AND
A테이블.속성1 = B테이블.속성1
A테이블.속성2 = C테이블.속성2
Inner Join
- 양쪽 테이블 모두에 조건을 만족하는 레코드만 출력
- 일반적인 join문을 생각하면 됌
Outer Join
- 조인을 할때에 조건을 만족하지 않더라도 포함 시키고자 할 때에 사용
1. Left Outer Join
- from 절 왼쪽에 있는 테이블1의 내용이 조건을 만족하지 않더라도 모두 출력
- 테이블1번에서 null 값인 것도 전부 출력
SELECT 컬럼1, 컬럼2, ......
FROM 테이블1 left outer join 테이블2
ON 조건식
만약 여러 테이블을 left outer join 해야할 때
SELECT 컬럼1, 컬럼2, ......
FROM 테이블1 left outer join 테이블2
ON 조건식 ---> 여기에는 join 에 필요한 컬럼명이 들어감 ( 예를들어 e.dno = d.dno )
left outer join 테이블3
ON 조건식 ---> 여기에는 join 에 필요한 컬럼명이 들어감 ( 예를들어 e.dno = d.dno )
WHERE
2. Right Outer join
- from 절 오른쪽에 있는 테이블은 조건을 만족하지 않더라도 모두 출력
- 테이블2번에서 null 값인 것도 전부 출력
SELECT 컬럼1, 컬럼2, ......
FROM 테이블1 right outer join 테이블2
ON 조건식
SELECT 컬럼1, 컬럼2, ......
FROM 테이블1 right outer join 테이블2
ON 조건식 ---> 여기에는 join 에 필요한 컬럼명이 들어감 ( 예를들어 e.dno = d.dno )
right outer join 테이블3
ON 조건식 ---> 여기에는 join 에 필요한 컬럼명이 들어감 ( 예를들어 e.dno = d.dno )
WHERE
일반적인 Inner Join 결과 충족되지 않는 값 출력 x

일반적인 outer Join 결과 충족되지 않는 값도 출력 O

outer join 2개 썻을 때 예시
- outer join 으로 null 값까지 표현 하였음.
SELECT e.eno "사원번호",d.dno "부서번호", d.DNAME "부서명",e.ENAME "사원명", m.ENAMe "관리자"
, TO_CHAR(e.HIREDATE,'yyyy/mm/dd DAY') "입사일"
, ROUND (MONTHS_BETWEEN(sysdate,e.hiredate),0) "근속월수"
, RPAD(SUBSTR(e.jumin,1,8),14,'*') "주민번호"
, ROUND ((e.SALARY+e.comm)*12*0.5,0) "상여금"
FROM emp e LEFT OUTER JOIN emp m on m.ENO = e.MGR LEFT OUTER JOIN dept d ON e.dno = d.dno
WHERE ROUND (MONTHS_BETWEEN(sysdate,e.hiredate),0) >=60
ORDER BY "근속월수" desc, e.ENAME;
Full Outer join
- 양쪽 테이블 모두 포함
Self Join
- 테이블 하나에서 어떤 컬럼이 자신의 또 다른 컬럼의 값을 참조하는 경우 사용
- 실제 물리적으로는 테이블이 하나인데 마치 두개인 것처럼 애칭을 주어 조인하는 것
- 아래 where 조건식에서는 사원의 mgr번호와 관리자의 eno번호는 참조관계에 있다는 개념
SELECT 사원.ename 사원이름, 관리자.ename 관리자이름
FROM emp 사원, emp 관리자
WHERE 사원.mgr = 관리자.eno
서브쿼리
- sql 쿼리 안에 다른 sql 쿼리가 삽입되는 것
- 서브쿼리가 조인보다 효율이 더 좋다고 한다.
- 서브쿼리가 올 수 있는 곳
- 서브쿼리 사용할 때 만약 메인쿼리에서 다른테이블의 속성에 참조해야하면 조인사용하는게 좋을 듯 싶다.
select절 - 단일 값만 반환 가능 (단일 값, sum, count 같은 것)
from절 - 반환 값이 테이블만 가능
where절 - 단일 값과, 복수 값 모두 가능.
참고블로그:
https://mjn5027.tistory.com/51
어떨 때는 서브쿼리쓰고 어떨때는 join 사용하냐?
내 생각에는 메인쿼리에서 출력해야할 속성이 다른테이블을 참조하지 않을 경우 서브쿼리로만 해도될 것 같다.
ex ) 메인쿼리 : select A1, A2, 테이블2.B1 from '테이블1'
이럴경우는 메인쿼리에서 테이블2의 값을 참조하기 때문에 조인을 사용하는게 좋을 것 같다..
상관 서브쿼리
- 서브쿼리의 조건식에서 메인쿼리의 테이블과 조건식이 필요한 경우
- 메인쿼리와 하위쿼리가 연관, 상관이 있어야 한다.
속성으로 복수의 값이 들어 와야할 것 같은 경우에 상관 서브쿼리를 사용한다.실제로는 복수의 값이 들어올 수 없는데, 복수의 값이 들어와야 할 것만 같은 경우에 select를 한번 더 써줘서 값을 단일로 불러오는 개념인 듯.. (확실하진 않으니 느낌만 이해할 것.)
select 상품코드 from 신발테이블 a1
where 매출 > ( select avg(매출) from 신발테이블 a2 where a2.매출 = a1.매출)
- 하위 쿼리에 where 절로 아래와 같이 표현 한다.
( WHERE a1.속성1 = a2.속성1)
Alias a1, a2은 모두 동일 테이블 '테이블 1' 의 별칭이다.
그냥, 약간 재귀함수 마냥 같은 테이블의 내용을 참조하는 할 경우에 저런 조건식으로 사용한다고 외우면 편합니다.
상관 서브쿼리 예시
아래 두 쿼리문은 결과가 똑같음 (굳이 표현해봤음)
SELECT bookNAME,(SELECT bookid FROM book a2 WHERE a2.bookid = a1.bookid) FROM book a1;
SELECT bookname, bookid FROM book;집합연산
1. Union
2. Minus
//모든 고객의 이름
SELECT NAME FROM customer
// 마이너스
minus
// 주문한 고객의 이름
SELECT NAME FROM CUSTOMER where custid IN (SELECT distinct custid from orders);
== 결과==
주문하지 않은 고객의 이름이 출력됨

3. EXISTS
- 서브쿼리의 결과가 존재하면 메인쿼리를 실행하고 존재하지 않으면 메인쿼리를 실행하지 않음
- 하위 쿼리가 '상관 서브쿼리 형식'으로 와야함
select 컬럼1, 컬럼2 from 테이블1
where exists
( select 컬럼3 from 테이블 2 where 테이블1.컬럼1 = 테이블2.컬럼4)
4. Intersect
연산의 우선순위를 주기 위해서 괄호를 꼭 잘 써줄 것
- 연산의 우선순위가 'and' > 'or' 이기 때문에 괄호 잘 묶어줄 것
- 'or' 연산 일 경우는 괄호 써주는 게 좋다
NVL 함수
- 특정 컬럼의 값이 NULL일 경우 다른 값으로 대체하는 함수
NVL (컬럼, 변환할 값)

- id number값을 1씩 늘리기
- 현재 최대 값을 구한 후 만약 null일 경우 0으로 채우고 +1을 해주는 개념
SELECT NVL(MAX(custid),0) +1 FROM customer100;sysdate 함수
- 오늘을 나타내는 함수
숫자 내장함수
| 1 | ABS (값) | - 절대 값을 반환하는 함수 |
| 2 | ceil (값) | - 무조건 올림수로 반환하는 함수 |
| 3 | floor (값) | - 무조건 버림수를 반환하는 함수 |
| 4 | round (값, 자리수) | - 반올림을 반환하는 함수 - 자리수가 0이면 정수부만 표시 (37.0 -> 37) - 자리수가 1이면 소수점 첫번째 자리 까지 표시 (37.89 -> 37.9) - 자리수가 -1이면 십의자리까지 표시 |
| 5 | log (밑, X) | - 말그대로 수학 log 함수이다 - 밑 10 , X=100 이면 2를 반환 |
| 6 | power (숫자, n제곱) | - 제곱 값을 반환 (2^3) -> 8 반환 |
| 7 | sqrt | - 제곱 승을 반환 (9) -> 3 반환 |
| 8 | sign | - 결과 값이 양수 = 1 반환 - 결과 값이 음수 = -1 반환 - 결과 값이 0 = 0 반환 |
ABS (절대 값)

CEIL (올림 수)

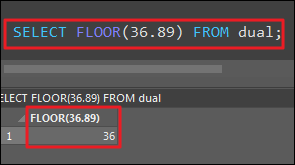
FLOOR (버림 수)
ROUND (반올림)
예시1)


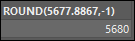

예시2) 평균 백원 단위로 반올림
ROUND(avg(saleprice), -2)

POWER (제곱 값 반환)

sqrt

문자 내장함수
| CHR ( 정수 ) | 정수 아스키코드를 문자로 반환 |
| CONCAT ('문자열1', '문자열2') | 두 문자열 연결 |
| INITCAP ('문자열') | 단어의 첫 글자를 대문자로 변환 |
| LOWER ('문자열') | 문자열을 모두 소문자로 변환 |
| UPPER ('문자열') | 문자열을 모두 대문자로 변환 |
| LPAD ('문자열', 정수형, '채울글자') | 정수만큼 자리수에 문자열을 채우는데 왼쪽에 채울글자를 채워라 |
| RPAD ('문자열', 정수형, '채울글자') | 정수만큼 자리수에 문자열을 채우는데 오른쪽에 채울글자를 채워라 |
| REPLACE('문자열1', '문자열2', '문자열3') | '문자열1'에서 '문자열2'의 글자를 '문자열3'으로 바꿔라 |
| TRIM (c FROM s) | 양쪽 공백을 삭제 |
| LTRIM (문자열1, 문자열2) | 왼쪽 공백 제거 |
| RTRIM (문자열1, 문자열2) | 오른쪽 공백 제거 |
| SUBSTR(문자열,시작위치,길이) | 문자열의 시작위치에서 길이만큼 잘라서 반환 |
| LENGTH (문자) | 문자열의 길이를 반환 |
| ASCII (값) | 문자를 정수형으로 반환 |
| instr ('문자열', '찾을 문자') instr ('문자열1', '문자열2', 숫자1) |
- 문자열에 특정 문자열의 위치를 반환 - 문자열1로부터 숫자1인덱스 이후에 나오는 문자열 2의 위치 |
CHR
- 정수에 해당하는 아스키 코드 반환 ( 65 -> 'A' )

CONCAT
- 두 문자열을 합하여 반환

INITCAP
- 단어의 첫글자를 대문자로 반환

lower
- 소문자로 변환

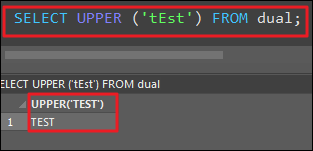
UPPER
- 대문자로 변환
TRIM
- 좌우 공백 제거 (공백 좌우 3개씩 6개)ㅇ
- length로 공백 제거 되었는지 표현하였음

LTRIM
- 왼쪽 공백 제거 (공백 좌우 3개씩 6개)
- length로 공백 제거 되었는지 표현하였음

RTRIM
- 오른쪽 공백 제거 (공백 좌우 3개씩 6개)
- length로 공백 제거 되었는지 표현하였음

length
- 문자열의 길이를 반환하는 함수
- length로 공백 제거 되었는지 표현하였음

ASCII
- 문자의 정수형 값 반환

INSTR
- 문자열에서 몇번째에 있는 문자인지 반환
예시1

예시2
이메일에서 우선 '@골뱅이'의 위치를 찾고 그 이후에 나오는 'dot(점 . )' 의 인덱스를 반환

SUBSTR
- 문자열을 잘라내어 반환
예시1
이름의 첫글자를 반환
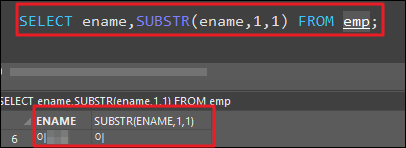
예시2 - 여성 서교동에사는 여성직원들의 정보를 출력
INSTR 함수로 주민번호 가운데 있는 '대시(-)'의 인덱스를 반환받고
SUBSTR 함수로 '대시(-)'의 인덱스부터 1글자 (뒷자리 첫번째)가 2 또는 4라면 여자
SELECT e.jumin, e.ename 사원이름 , m.ename 관리자이름,
e.email 사원이메일, m.email 관리자이메일, e.dno,
d.dname, (e.salary +e.COMM)*12
FROM emp m, emp e, dept d
WHERE (SUBSTR(e.jumin, INSTR(e.jumin,'-')+1, 1) in ('2','4')) AND d.DLOC LIKE '%서교동%'
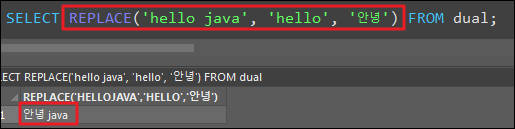
AND m.eno = e.mgr AND e.dno = d.dno ORDER by e.dno, e.ename;REPLACE
- '문자열1'에서 '문자열2'의 글자를 '문자열3'으로 바꿔라
LPAD
- 문자열을 자릿수 만큼 공간을 잡아 오른쪽에 정렬하여 출력하고 나머지 왼쪽 빈칸은 채울글자로 채웁니다.
RPAD
- 문자열을 자릿수 만큼 공간을 잡아 왼쪽 정렬하여 출력하고 나머지 오른쪽 빈칸은 채울글자로 채웁니다.
예시1 - 이름의 첫 글자를 출력하여 나머지는 * 로 마스킹
SELECT RPAD(SUBSTR(ename,1,1),LENGTH(ename),'*') FROM emp;
예시2 -아래와 같이 출력하는데 주민번호는 마스킹 처리하라
select e.eno, e.ename, SUBSTR(e.email, 1, INSTR(e.email, '@') -1) id,
rpad(SUBSTR(e.jumin, 1, 8) , 14, '*') jumin,
LPAD(e.salary+e.comm , 10, 0 ) salary
FROM emp e, emp m
WHERE e.mgr = m.eno AND
e.ename ='김한희'
ORDER BY e.salary + e.comm DESC, e.ename;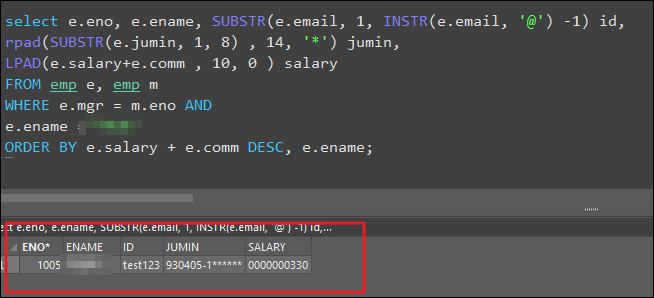
날짜 관련 함수
| to_date(char, datetime) | 문자열 데이터를 날짜형으로 반환 TO_DATE ('2014-02-14', 'yyyy-mm-dd') = 2014-02-14 |
| TO_CHAR (date, datetime) | 날짜형 데이터를 문자열로 반환 TO_CHAR (TO_DATE ('2014-02-14', 'yyyy-mm-dd')) = 20140214 |
| ADD_MONTHS(date, 숫자) | date형의 날짜에서 지정한 만큼 더함 (1 : 다음달, -1: 이전달) |
| LAST_DAY(date) | date형의 날짜에서 월의 마지막 날을 반환 LAST_DAY(TO_DATE('2014-02-14', 'yyyy-mm-dd')) = 2014-02-28 |
| SYSDATE | 시스템 상의 오늘 날짜를 반환 |
SYSDATE
예시 - 어제, 오늘, 내일

TO_CHAR
TO_CHAR (날짜, 형식 문자)
TO_CHAR (TO_DATE ('2014-02-14', 'yyyy-mm-dd')) = 20140214
년 : yyyy / yy
월 : mm
일: dd
요일 : d ('3' 출력, 화요일 = 3)
요일 : day ('화요일' 출력)
요일 약어 : dy ('화' 출력)
시: hh
분: mi
초: ss
- 날짜형 데이터를 문자열로 반환
사용 예시들
SELECT TO_CHAR(SYSDATE, 'yyyy') FROM dual; // 2022
SELECT TO_CHAR(SYSDATE, 'yy') FROM dual; // 22
SELECT TO_CHAR(SYSDATE, 'mm') FROM dual; // 01
SELECT TO_CHAR(SYSDATE, 'dd') FROM dual; // 일
SELECT TO_CHAR(SYSDATE, 'hh') FROM dual; // 시
SELECT TO_CHAR(SYSDATE, 'mi') FROM dual;
SELECT TO_CHAR(SYSDATE, 'ss') FROM dual;
SELECT TO_CHAR(SYSDATE, 'yyyy-mm') FROM dual;
SELECT TO_CHAR(SYSDATE, 'yyyymm') FROM dual;
SELECT TO_CHAR(SYSDATE, 'yyyy-ss') FROM dual;TO_DATE
- 문자열 데이터를 날짜형으로 반환

ADD_MONTHS
ADD_MONTH (날짜, 숫자)
- 날짜에 숫자 개월수 만큼 더해 반환

LAST_DAY
LAST_DAY(날짜)
- 이달의 마지막 날을 반환

MONTHS_BETWEEN
- 두 날짜 사이의 개월 수를 반환
MONTHS_BETWEEN (최근 날짜1, 올드 날짜2)
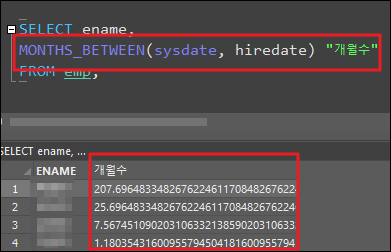
DECODE 함수
DECODE(컬럼, 값1, 결과1, 값2, 결과2, 결과3)
컬럼의 값이 값1이면 결과1를 반환
컬럼의 값이 값2이면 결과2를 반환
그 나머지이면 결과 3을 반환

테이블 복사하기
CREATE TABLE 새테이블명 AS SELECT * FROM 복사할테이블명
ROWNUM
- 오라클 내부적으로 생성되는 가상 컬럼으로 SQL 조회 결과의 순번을 나타냄
- SELECT 결과에 행 번호를 매겨주는 키워드
1. ROWNUM 단일로만 사용 -- 행번호가 같이 출력됨
2. ROWNUM ..... WHERE ROWNUM <=3 -- 행번호와 3행만 출력됨
3. WHERE ROWNUM <=3 -- 속성에 ROWNUM 안쓰면 행번호는 출력 안되고 3행만 출력됨
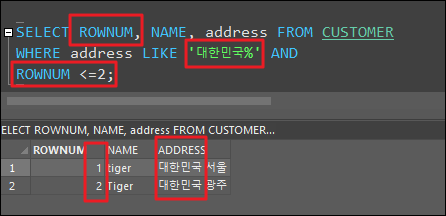
- ROWNUM과 ORDER BY를 같이 사용할 때에는 order by 결과를 먼저 동작하도록 하기 위하여 서브쿼리를 사용해야함
예시1
SELECT rownum, custid, NAME
FROM (SELECT custid,NAME FROM customer ORDER BY CUSTID DESC);
예시2
1. 1번은 SELECT가 선 진행하여 5줄 뽑아 온 후에 ORDER BY 가 실행
2. 2번은 ORDER BY 선 진행 후에 정렬된 데이터 기준으로 5줄을 출력

예시 3
(중간에 있는 데이터를 가져올 때는 아래와 같이 서브쿼리를 2번 사용해야함)

1. 맨 아래 자식쿼리에서 선 정렬 후 (order by)
2. 상위 자식쿼리에서 ROWNUM을 붙히고 (rownum)
3. 메인 부모 쿼리에서 출력
***상위 자식 쿼리에서 Rownum의 명칭을 n으로 별칭 설정 후, 메인쿼리의 where에서 n을 사용해야함
부속질의 (서브쿼리)
스칼라 부속질의
1. SELECT 절
- 단일 행이 오도록 해야함
- 상관/비상관 서브쿼리를 사용하여 진행 (서브 쿼리의 where 절로 상관서브쿼리임을 나타내는 것임)
- 당연한 건데, 상관서브쿼리를 이용한 이유는 단일 값을 리턴 받기 위함.
상관 서브쿼리 사용
(해당 예시의 경우 join을 해도 되지만 상관서브쿼리를 이요하여 진행하였음)
SELECT custid ,
(SELECT NAME FROM customer c WHERE c.custid= o.CUSTID) "name",
SUM(saleprice) FROM orders o GROUP BY custid;2. UPDATE 절
UPDATE orders
SET bookname =
(SELECT bookname FROM book WHERE book.BOOKID = orders.BOOKID)인라인 뷰 ( FROM 절 )
- FROM 절에서 결과를 뷰(view)로 반환하기 때문에 인라인 뷰라고 함.
중첩질의 ( WHERE 절 )
- 결과를 한정시 키기 위해 사용
중첩 질의 연산자
| 비교 | = , > , < , >=, <=, <> |
| 집합 | IN, NOT IN |
| 한정 | ALL, SOME(ANY) |
| 존재 | exists, not exists |
다중행 연산자란?
- 서브쿼리가 where절에 사용될 때에 서브쿼리의 건수가 여러 건 일 때 사용하는 연산자로 in, not, in all some, any 등이 존재
- all, any(some) 서브쿼리의 개수가 여러개 일 때 사용 (>, <, >=, <=)
all
- 3번 고객의 반환 'saleprice' 반환 값이 6개 나오고 all 연산자를 사용함으로써 해당 반환 값을 모두 검사
예시 - 3번고객이 주문한 금액보다 큰 금액을 표현

EXISTS, NOT EXISTS
- 서브쿼리에 데이터의 존재 유무를 확인
- EXISTS 서브쿼리에 데이터가 있으면 메인쿼리 동작
- NOT EXISTS 서브쿼리에 데이터가 없으면 메인쿼리 동작
뷰(VIEW)
- 하나 이상의 테이블을 합하여 만든 가상의 테이블
- 자주 사용하는 복잡한 SQL문을 미리 VIEW로 만들어서 사용
CREATE VIEW 뷰이름[(열이름 [ ,....n])]
AS SELECT 문
장점
- 편리성 및 재사용성 : 자주 사용하는 복잡한 SQL문을 미리 VIEW로 만들어서 사용
- 보안성 : 각 사용자 별로 필요한 데이터만 선별하여 보여줄 수 있음. 중요한 질의의 경우 질의 내용을 암호화 할 수 있음 (개인정보, 급여,건강 같은 민감 정보를 제외한 테이블을 만들어 사용)
- 독립성 제공 : 미리 정의된 뷰를 일반 테이블처럼 사용할 수 있음
뷰 (VIEW) 생성화면

VIEW로 INSERT, UPDATE, DELETE
- VIEW 로 레코드를 INSERT, UPDATE, DELETE 를 하게 되면 부모 테이블로 추가/수정/삭제가 된다.
- 만약, VIEW 생성 시에 조건에 맞지않는 레코드를 추가하게 되면 모테이블에는 추가는 되는데, VIEW 에는 조건식이 맞지 않기 때문에 당연히 나타나지 않는다.


WITH CHECK OPTION
- 뷰 생성시에 사용한 조건식에 맞는 레코드만 추가 /수정 하도록 하기 위한 옵션
CREATE VIEW 뷰이름 AS SELECT ~~ 조건식 WITH CHECK OPTION;
WITH READ ONLY
- 읽기만 가능한 뷰 생성 하는 옵션
CREATE VIEW 뷰이름 AS SELECT ~~ 조건식 WITH READ ONLY;

문 제
같은 성씨찾기
SELECT SUBSTR(eNAME,1,1), COUNT(*) FROM emp
GROUP BY SUBSTR(eNAME,1,1);상관 서브 쿼리 사용해서 나이 구하기
상관 서브 쿼리가 사용된 부분은 3번째 줄에서 사용.
왜 사용했냐면 속성 값으로 조건에 따라 1900을 더할 수도 있고, 2000을 더할 수도 있도록 하기 위해서
상관 서브 쿼리문을 사용
SELECT eno, ename, jumin,
TO_CHAR(SYSDATE, 'yyyy') - (SUBSTR(jumin, 1, 2) +
(SELECT DECODE( SUBSTR(jumin,8,1), '1',1900, '2',1900, 2000)
FROM emp e2 where e1.eno = e2.eno)) age
FROM emp e1;
팁 (tip)
집계함수 사용시 주의점
- NULL + 숫자 = NULL
- NULL 은 집계함수 실행 시 포함되지 않음
- count는 만족하는 레코드의 값이 없으면 0을 반환
- sum, avg는 값이 없으면 null을 반환
가상테이블 (dual 테이블)
dual 테이블 : 가상의 테이블
사용법 : SELECT ABS(-78) FROM dual;
쿼리문 실행 순서
FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BY