SQL 기능에 따른 분류
1. 데이터 정의어(DDL)
- 테이블이나 관계의 구조를 생성하는 데 사용
- 테이블을 만들거나 테이블의 구조를 변경하거나 데이터를 삭제하는 명령
CREATE, ALTER, DROP
2. 데이터 조작어(DML)
- 테이블에 데이터를 검색, 삽입, 수정 ,삭제하는데 사용
SELECT, INSERT, DELETE, UPDATE
3. 데이터 제어어(DCL)
- 데이터의 사용 권한을 관리
GRANT, REVOKE 등
데이터 정의어 (DDL) - CREATE
- 테이블을 생성하는 명령
CRATE TABLE 테이블이름
( 컬럼이름 데이터타입 제약사항들[ NOT NULL | UNIQUE | DEFAULT | CHECK | 등]
..
..
)
NOT NULL
: NULL을 허용하지 않음(무조건 값을 넣어라)
UNIQUE
: 중복 불가능, NULL 허용
DEFAULT
: 기본 값
CHECK
: 컬럼의 값이 특정 조건식을 만족 해야함
FOREIGN KEY
:참조키 설정, 다른 테이블의 값을 참조
:부모테이블의 PK를 FK로 설정할 수 있음
PRIMARY KEY
: 기본키 설정, 중복 불가, 생략 불가
: 두개 이상의 컬럼을 한 쌍으로하여 기본키로 설정할 수 있음
: 두개 이상의 컬럼을 기본키로 설정할 경우
테이블 생성 시 테이블 레벨에서 PRIMARY KEY (속성1, 속성2)
| FOREIGN KEY | NOT NULL | PRIMARY KEY | UNIQUE | CHECK | DEFAULT | |
| 생략 | O | X | X | O | O | DEFAULT 값 |
| 중복 | O | O | X | X | O | O |
추가 설명 - CHECK
- 컬럼의 값이 특정 조건식을 만족 해야함
- 아래와 같이 제약조건을 설정할 수 있음.

Check 제약조건 위배시 - 에러 출력
데이터 정의어 (DDL) - ALTER
- 테이블 구조 변경하는 명령
- 테이블에 새로운 컬럼명을 추가 / 삭제
- 제약조건을 추가 / 삭제
- 자료형 변경, PK, FK 설정 가능.
컬럼 추가
ALTER TABLE 테이블명 ADD 컬럼이름 자료형;
컬럼에 PK 추가
ALTER TABLE 테이블명 ADD PRIMARY KEY (컬럼이름, [컬럼이름2]);
- 단, 이미 컬럼 데이터로 null값이 들어가 있는 상태면 바꿀 수 없음
컬럼에 FK 추가
ALTER TABLE 테이블명 ADD FOREIGN KEY(컬럼이름) REFERENCES 부모테이블명(컬럼명)
- 단, 이미 컬럼 데이터로 null값이 들어가 있는 상태면 바꿀 수 없음
컬럼에 CHECK 추가
ALTER TABLE 테이블명 ADD CHECK (price<=20000);
컬럼 자료형 변경
ALTER TABLE 테이블명 modify 컬럼이름 새로운자료형
컬럼 NOT NULL 설정
ALTER TABLE 테이블명 modify 컬럼이름 NOT NULL
컬럼 삭제
ALTER TABLE 테이블명 DROP COLUMN 컬럼이름
데이터 정의어 (DDL) - DROP
- 테이블 삭제하는 명령
DROP TABLE 테이블명;
관계형 데이터베이스에서는 테이블을 개체(Entity)라고도 표현한다.
개체무결성
- 모든레코드 (튜플)는 PK로 설정된 주식별자에 의해서 구별이 가능해야 함을 말한다.
- pk는 null이 될 수 없고, 중복을 허용하지 않는다.
- 이것을 만족하지 않는 경우를 '개체 무결성에 위배된다'라고 말한다.
참조무결성
- 참조키로 설정된 컬럼의 값은 반드시 부모테이블 존재해야한다
- 이것을 만족하지 않는 경우를 '참조 무결성에 위배된다'라고 말한다.
on delete cascade
- 부모테이블의 레코드를 삭제 할 때에 연쇄적으로 자식의 레코드를 삭제하도록 설정
- 자식 테이블 생성 시에 설정 해줘야 함
FOREIGN KEY ( 자식 속성 ) REFERENCES 부모테이블(부모속성) ON DELETE CASCADE
데이터 조작어 (DML) - SELECT
SELECT [ ALL | DISTINCT ] 속성이름
FROM 테이블이름(들)
[WHERE 검색조건(들)]
[GROUP BY 속성이름]
[HAVING 'GROUP BY'에 대한 검색조건(들)]
[ORDER BY 속성이름 [ASC | DESC]]
WHERE
비교 : = , <>, <, <=, > >=
범위 : BETWEEN -- BETWEEN A AND B
집합 : IN, NOT IN -- price IN(10000, 20000, 30000)
패턴 : LIKE ( bookname LIKE '축구의 역사' ) ) , %와 같이 많이 사용 됌.
NULL : IS NULL, IS NOT NULL
복합 : AND, OR, NOT
- 'IN'과 'NOT IN' 은 각각 'OR'과 '<> AND' 로 표현할 수 있다.
'NOT IN' 과 '<> AND' 예시
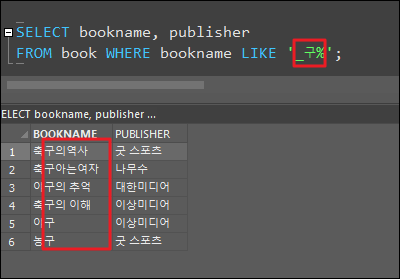
- 와일드문자
'축구'가 포함된 속성 출력

두번째 글자에 '구'가 포함되고 뒤에는 아무 글자나 와도 됌
- 언더바( _ ) 로 인해 첫글자 패스
- 퍼센트 ( % ) 로 인해 '구'이후의 글자 아무거나 와도 상관없음
ORDER BY
- 특정 컬럼을 기준으로 자료를 정렬하여 검색하고자 할 떄 사용.
1. order by 컬럼이름 [asc, desc]
2. order by 컬럼1, 컬럼2
--> 이 경우 컬럼1로 먼저 정렬 되고, 정렬 되던 도중 같은 값이 존재하면 컬럼2로 정렬됨
----------------------------------
asc : 오름차순 (기본, 생략가능)
desc : 내림차순
- order by 로 속성 명이 2개가 오면 뒤에 온 필드명은 선행 필드로 정렬 후 값이 동일 할 경우 후행 필드로 정렬됨
'publisher' 컬럼으로 정렬 후
컬럼의 데이터가 동일할 경우 가격순으로 내림차순 정렬

집계함수
- 컬럼 별 총합, 평균, 최대 값, 최소 값, 개수를 파악하기 위한 함수
- AS 키워드로 별칭을 줄 수 있다
- 집계함수의 결과는 다른 컬럼의 이름을 함께 출력할 수 없음
SUM (총합)
AVG (평균)
MAX (최대 값)
MIN (최소 값)
COUNT (개수)
-> 컬럼에 null이 있으면 COUNT(*)로 해야 null값 까지 카운트
-> 컬럼에 null이 있을 때 COUNT(컬럼명) 하면 null값 카운트 불가능
---------------------------------------
예시
select SUM (saleprice) from orders;
select AVG (saleprice) from orders;
집계함수의 결과는 다른 단일 컬럼의 이름을 함께 출력할 수 없음

GROUP BY 와 집계함수
- 집계함수의 결과는 다른 단일 컬럼의 이름을 함께 출력할 수 없는데,(한줄만 표현됨)
- 고객 별로 총 추문건수를 알고 싶을 경우 GROUP BY와 같이 사용하여 표현 가능
- 만약 group by 안쓰면 전체 행의 개수와, saleprice의 합계만 1행 2열로 출력될 것임
Group by 미 사용 시 한줄로 밖에 표현 못함.

출판사 컬럼을 Group by로 묶어주어 아래와 여러 데이터 표현 가능
출판사 별로 출판한 책 개수를 표현한 것임

HAVING
- GROUP BY 절에 나타난 결과에 대해 조건식을 표현하고자 할 때에 사용
- 즉, GROUP BY의 where이라고 생각할 것
- 조건식에서는 alias를 사용할 수 없는 듯
ex) alias가 "건수"라고 한다면 '건수 >=2' 이런 식으로 사용 불가능 - 집계함수 (count, sum 등)의 결과에 조건을 주고싶을 때 having이 들어가야함
데이터 조작어 (DML) - INSERT
INSERT INTO 테이블명 VALUES (값 리스트);
- 값 리스트는 테이블의 구조와 동일해야 함 (타입, 순서 등)
INSERT INTO 테이블명 [(속성리스트)] VALUES (값 리스트);
- 값 리스트는 속성리스트의 구조 동일해야함
- 테이블의 제약조건에 'NOT NULL', 'PK'가 존재한다면 속성 리스트에 반드시 포함해야한다
INSERT INTO 테이블명1 [(속성리스트)] SELECT 속성 FROM 테이블명2
- SELECT 구문의 테이블명2의 레코드들을 테이블명1로 INSERT 가능
데이터 조작어 (DML) - UPDATE
- 조건식이 없으면 모든 레코드의 값이 수정 됨
- 조건식이 있으면 조건에 맞는 레코드만 수정 됨
UPDATE 테이블명
SET 속성이름1 = 값1 [ , 속성이름2 = 값2, ........]
where [<검색조건>];
UPDATE 테이블명
SET 속성이름1 = ( 서브쿼리 SELECT )
데이터 조작어 (DML) - DELETE
DELETE 테이블명 [where 조건식]
ROLLBACK
- DML 작업 시 가장 최근의 commit 지점까지 취소
- DCL, DDL은 자동 커밋
- 아래 예시와 같은 경우 Rollback 불가능
작업 순서
1. update 작업 진행
2. create table 작업 진행
3. Rollback하여 1번의 update 진행 전으로 RollBack 이 가능한가?
--> 불가능, 이유는 2번의 create 작업을 진행하면 자동 commit이 되기 때문에 1번 update 전으로 rollback이 무시됨
반응형
'개발 > 데이터베이스' 카테고리의 다른 글
| 오라클 쿼리 실행 시간 확인 방법 (0) | 2022.04.25 |
|---|---|
| (데이터베이스) 서브쿼리, 상관서브쿼리 (0) | 2022.04.22 |
| (데이터이스 ) Join (Inner Join, Outer Join, full, Self Join) (0) | 2022.04.21 |
| 데이터베이스 (Database) (0) | 2022.04.16 |
| SQLGate (0) | 2022.04.15 |



댓글